Seguramente ya escuchaste hablar de Unicode, pero… ¿sabes cómo soportarlo correctamente en tus aplicaciones? Y ¿sabes realmente cómo funciona? Este artículo usa el contenido de mi conferencia « Pourquoi strlen(«🍕») != 1 ? », así que si estuviste en el Foro PHP 2016, puedes cerrar esta pestaña y retomar tu actividad normal.
En el caso contrario, déjame contarte la historia de Unicode y cómo usarlo en un proyecto PHP.
La codificación
Nuestras computadoras hablan con bits: 1, 0. Nosotros comunicamos con texto. Por eso se necesita una técnica para traducir el texto en bits y los bits en texto. Además, nuestra computadora debe comunicarse con otras computadoras, impresoras, teclados.
Eso dio lugar a la invención de la codificación (por 🇫🇷 el ingeniero Mimault con su código Baudot). Se trata de una lista de reglas para transformar un dato en los dos sentidos; en el caso del texto, significa que « 01100001 » vale « a ».
En los inicios de la informática moderna, era un caos: cada constructor codificaba a su manera (¿una buena técnica para mantener a sus clientes?). Raras veces un documento salía del sistema en el cual había sido escrito y la interoperabilidad no existía. Pero no podía seguir así, en 1963, el «American National Standards Institute» (ANSI), lanzó un comité para producir el estándar que conocemos hoy en día bajo el nombre de ASCII.
Fue un camino largo y difícil: qué caracteres incluir, en qué orden, qué compatibilidad con los no-estándares existentes, entre otros. Pero fue en este estándar que se establecieron las bases para compartir texto en informática.
American Standard Code for Information Interchange
Publicado en 1963, esta codificación utiliza 7 bits por carácter, lo que ofrece 127 posibilidades.
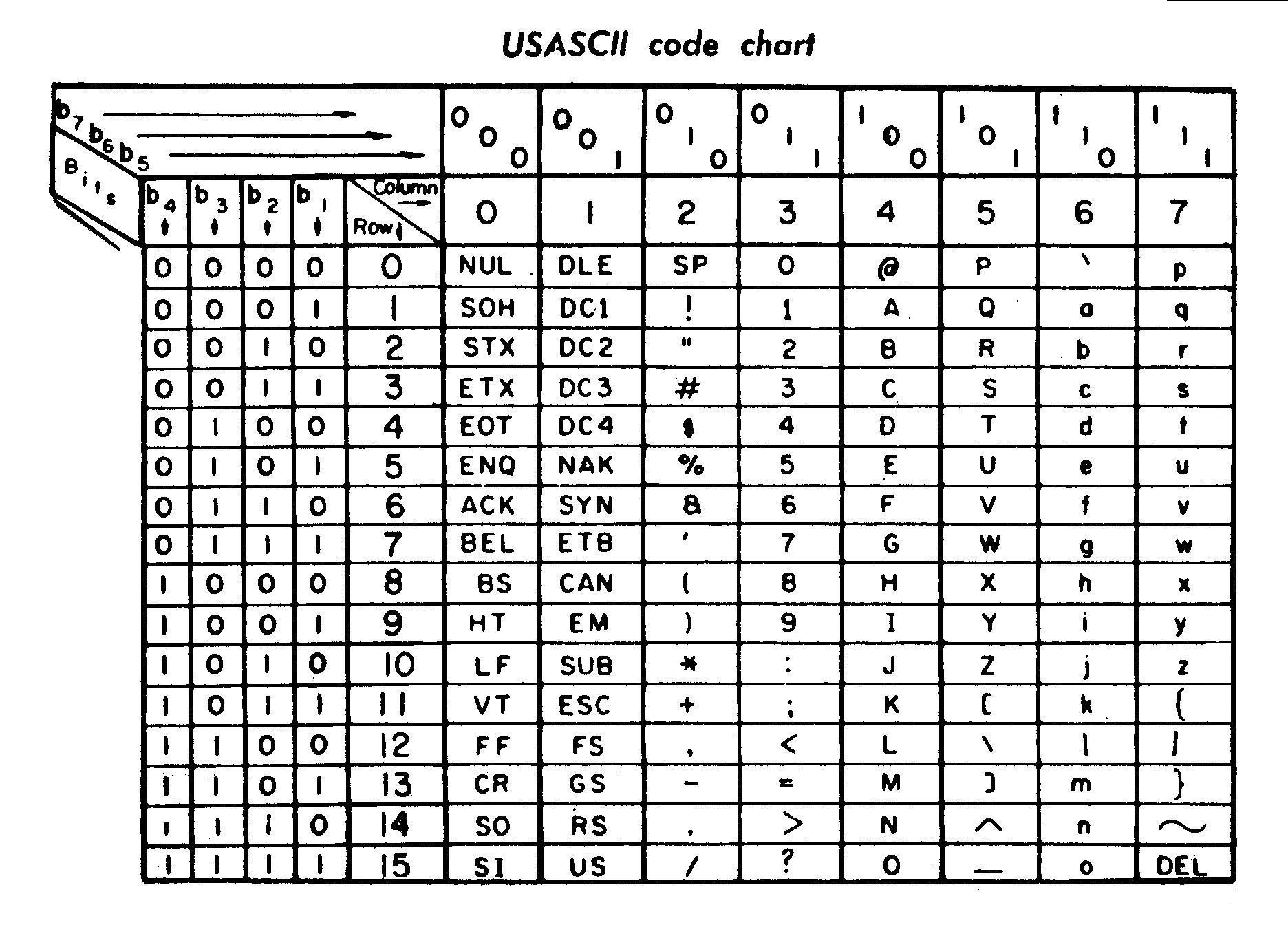
Como lo puedes constatar en esta tabla, se encuentran caracteres de control (que en su mayoría ya no sirve para nada), puntuación, cifras y el alfabeto inglés con mayúsculas y minúsculas.
Creo que mi preferido es ␙ (End of medium): permitía avisar cuando ya no había papel o banda magnética 📼.
En resumen, era excelente para los Estadounidenses 🇺🇸. Pero realmente solo para ellos: en efecto, no se encuentra ninguna letra acentuada en este estándar. En 1972, los primeros CPU 8 bits llegan (gracias IBM), entonces hay una oportunidad que aprovechar: ¡con 8 bits, es posible codificar 255 caracteres!
El mundo entero se lanza a codificar é, ß, ü, ä, ö, å, sin dejar de lado la compatibilidad con ASCII (y por lo tanto con la mayoría de los sistemas informáticos de la época).
Para resumir, es a partir de ese momento que cada país tuvo su variante:
– ISO 8859-2 Western and Central Europe
– ISO 8859-3 Turkish, Maltese plus Esperanto
– ISO 8859-4 Lithuania, Estonia, Latvia and Lapp
– ISO 8859-5 Cyrillic alphabet
– ISO 8859-6 Arabic
– ISO 8859-7 Greek
– ISO 8859-8 Hebrew
– ISO 8859-9 Western Europe with amended Turkish
– ISO 8859-11 Thai
– ISO 8859-14 Celtic languages
– ISO 8859-15 Added the Euro sign from ISO 8859-1…
Entonces si querías escribir en griego, utilizabas ISO 8859-7. Para el francés, utilizamos ISO 8859-1. Y para escribir francés en un documento en griego… era complicado (¡es decir «imposible»!).
La llegada de Internet y del Mojibake
Uno de los grandes problemas de la codificación es que el resultado final sigue siendo una sucesión de 1 y 0 que no llevan ninguna otra información. Entonces es imposible saber si un documento de texto fue escrito en ISO 8859-7 o en ISO 8859-11. Internet facilitó como nunca antes el intercambio de documentos a través del mundo y el problema se volvió muy visible.
¡Fue la edad de oro del MOJIBAKE! Es el nombre que lleva el bug de visualización ligado al uso de una codificación errónea al momento de la lectura de un carácter y el resultado ES INCREÃBLE.
NdT: unas líneas de código para reproducir este mojibake en PHP:
<?php
// Mojibake del cáracter Í
print("\n# Mojibake en la palabra \"INCREÍBLE\":\n");
print(iconv("ISO-8859-1", "UTF-8", 'INCREÍBLE') . "\n");
?>
El salvador Unicode
Publicado en 1991 (mucho antes de la Playstation, los Pokemons y el HTML), este nuevo estándar nació con tres principios clave:
– ser universal: soportar todos los idiomas;
– ser uniforme: representaciones binarias de tamaño fijo para ser fácil de descodificar;
– ser único: una sola interpretación posible por código.
Unicode 1.0 tenía 65536 «code points» disponibles y usaba 16 bits por carácter (UCS). Fue tal alivio que todo el mundo aprovechó la ocasión: Javascript, C, Java…
Pero lamentablemente los redactores de esta primera versión habían previsto demasiado poco. Desde 1993 más de la mita de los «code points» disponibles estaban asignados y faltaban todavía muchos idiomas.
Unicode 2.0 y UTF
En 1996, Unicode cambia de funcionamiento e introduce a UTF. Desde entonces, la codificación está separada de la lista de «code points»:
– Unicode designa el catálogo de «code points», que dispone ahora de 1.114.112 espacios ;
– UTF (Universal Character Set Transformation Format) designa la codificación.
Los diferentes UTF se diferencian por su manera de almacenar los «code points» y su compatibilidad con ASCII.
 UTF-8 es el más usado porque es compatible con ASCII: si escribes la letra «A», es la misma sucesión de 1 y 0 que estará almacenada, sin importar la codificación. Cuando sales del conjunto de caracteres ASCII, el número de bytes aumenta hasta un máximo de 4.
UTF-8 es el más usado porque es compatible con ASCII: si escribes la letra «A», es la misma sucesión de 1 y 0 que estará almacenada, sin importar la codificación. Cuando sales del conjunto de caracteres ASCII, el número de bytes aumenta hasta un máximo de 4.
En cuanto a UTF-16, tiene la particularidad de ser compatible con UCS, y entonces Unicode 1.0. Es una ventaja mayor, en particular para Javascript que pudo pasar a UTF-16 sin romper todas las cadenas literales. Sus desventajas son no ser compatible con ASCII y que los caracteres fuera de la BMP (Basic Multilingual Plane, los 65k caracteres más corrientes) ocupan dos pares UTF-16 (entonces 4 bytes). También es la codificación que fue elegida por PHP 6 en su época.
Y finalmente, UTF-32 es la codificación de tamaño fijo que permite almacenar en 4 bytes sin preocuparse (a costa de un desperdicio de espacio disco, ancho de banda, RAM…). Es el único que respeta la segunda regla de Unicode: ser uniforme.
No te compliques mucho: ¡UTF-8 es la codificación que necesitas! Actualmente es utilizado por 87% de la web (según W3Techs.com) y sin duda ya lo utilizas sin darte cuenta.
Hoy en día, Unicode es tan grande que dispone también de espacios de uso privado, que permite por ejemplo a los fans codificar el Klingon! Soporta oficialmente 135 escrituras, 267k «code points», emojis 🍻 y es recomendado por el W3C desde el HTML 4.
Este pasaje por Unicode 1.0 en 16 bits nos deja una herencia muy singular cuando probamos de contar la longitud de un texto en Javascript.
Herencia de Unicode 1.0 y longitud de un texto
Sabemos que un texto es una sucesión de bytes. Dependiendo de la codificación, estos bytes tienen un sentido diferente (o hasta no tienen ningún sentido):
– 01000001 01100011 11100001 produce «Acá» en ISO-8859-1 ;
– 01000001 01100011 11100001 produce «Acف» en ISO-8859-6.
NdT: algunas líneas de código PHP para reproducir:
<?php
function binary_to_utf8($binary_string, $encoding) {
$hex=base_convert($binary_string, 2, 16); // Si $binary_string vale "11001001", produce "c9"
$codepoint=pack('H*', $hex); // Produce "\xc9"
$ch = iconv($encoding, "UTF-8", $codepoint ); // Si $encoding vale "ISO-8859-1", produce "É"
return $ch;
}
function utf8_to_binary($utf8_string, $encoding) {
$codepoint = iconv("UTF-8", $encoding, $utf8_string ); // Si $utf8_string vale 'í' y $encoding vale "ISO-8859-1", produce "\xed"
$hex=unpack('H*', $codepoint); // Produce "ed"
$binary_string=base_convert($hex[1], 16, 2); // Produce "11101101"
return $binary_string;
}
// Códigos binarios de "Acá"
print("\n# Códigos binarios de \"Acá\" (códificación ISO-8859-1):\n");
print(utf8_to_binary("A", "ISO-8859-1") . "\n"); // produce "01000001"
print(utf8_to_binary("c", "ISO-8859-1") . "\n"); // produce "01000001"
print(utf8_to_binary("á", "ISO-8859-1") . "\n"); // produce "01000001"
// Codepoints "01000001" "01100011" "11100001" en ISO-8859-1
print("\n# Representación de los tres caracteres \"01000001\" \"01100011\" y \"11100001\" en la códificación ISO-8859-1:\n");
print(binary_to_utf8("01000001", "ISO-8859-1") . "\n"); // produce "A"
print(binary_to_utf8("01100011", "ISO-8859-1") . "\n"); // produce "c"
print(binary_to_utf8("11100001", "ISO-8859-1") . "\n"); // produce "á"
// Codepoints "01000001" "01100011" "11100001" en ISO-8859-6
print("\n# Representación de los tres caracteres \"01000001\" \"01100011\" y \"11100001\" en la códificación ISO-8859-6:\n");
print(binary_to_utf8("01000001", "ISO-8859-6") . "\n"); // produce "A"
print(binary_to_utf8("01100011", "ISO-8859-6") . "\n"); // produce "c"
print(binary_to_utf8("11100001", "ISO-8859-6") . "\n"); // produce "ف"
?>
También ciertos caracteres pueden ser compuestos:
– la letra «á» con el teclado: 11000011 10100001;
– la letra «á» compuesta con «a» y «◌́» : 01100001 11001100 10000001.
NdT: algunas líneas de código PHP para reproducir:
<?php
// También ciertos carácteres pueden ser compuestos:
print("\n# Representación de \"á\" a partir de la tecla: \"11000011 10100001\"\n");
print(binary_to_utf8("1100001110100001", "UTF-8") . "\n"); // produce "á"
print("\n# Representación de \"á\" a partir de la composición de los carácteres \"a\" y \"◌́\": \"01100001 11001100 10000001\"\n");
print(binary_to_utf8("01100001", "UTF-8") . "\n"); // produce "a"
print(binary_to_utf8("1100110010000001", "UTF-8") . "\n"); // produce "◌́"
print(binary_to_utf8("011000011100110010000001", "UTF-8") . "\n"); // produce "A"
?>
Entonces hay que definir qué contar: ¿»code point»? ¿byte ? ¿grafema? Tomemos por ejemplo la «Œ». Se trata del «code point» LATIN CAPITAL LIGATURE OE (U+0152) y en UTF-8 ocupa dos bytes: 0xC5 y 0x92. Para tu información, esta presente en ISO-8859-15 pero no en ISO-8859-1!
// PHP :
echo strlen("Œ"); // 2, el número de bytes
echo mb_strlen("Œ"); // 1
// JavaScript :
'Œ'.length; // 1
// Python :
>>> len('Œ') // 2
>>> len(u'Œ') // 1 con el flag Unicode
Como puedes darte cuenta en PHP obtenemos 2 con strlen pero 1 con mb_strlen. JavaScript nos da el tamaño correcto y Python se comporta como PHP.
Ahora si probamos con 🍕 en vez de Œ :
// PHP :
echo strlen("🍕"); // 4, el número de bytes
echo mb_strlen("🍕"); // 1
// JavaScript :
'🍕'.length; // 2
// Python :
>>> len('🍕') // 4
>>> len(u'🍕') // 1 con el flag Unicode
El comportamiento es coherente para PHP y Python, sin embargo, Javascript nos devuelve 2 en vez de 1!
Como lo vimos antes, en Javascript, si sales de la BMP, UTF-16 necesita dos pares de bytes y la API se quedó en el estado donde length cuenta simplemente los grupos de 16 bits. Mi trozo de pizza se compone de dos pares de bytes (compatible UTF-16 únicamente), y solo tu navegador es capaz de renderizar y saber que en realidad se trata de un solo carácter, no el motor Javascript. Por eso la cifra 2 devuelta por length.
En PHP, todo es simple: Unicode no está soportado, pero el lenguaje es totalmente compatible, nunca va a realizar operaciones raras o incoherentes. strlen cuenta en bytes, todas las manipulaciones mediante la API de base hacen igual, y las comparaciones son binarias.
Para manipular cadenas de caracteres, se recomienda entonces usar las funciones Multibyte:
echo "🍕"[0]; // �
echo mb_substr("🍕", 0, 1, 'UTF-8') // 🍕
Estas funciones mapean las funciones de base con un prefijo mb_:
– mb_check_encoding
– mb_convert_encoding
– mb_convert_case
– mb_strlen
– mb_strtolower…
A modo de comentario, te darás cuenta que la función utf8_encode no sirve para nada y fue muy mal nombrada: lo único que hace es convertir de ISO-8859-1 a UTF-8…
var_dump('€'); // string(3) "€"
var_dump(utf8_encode('€')); // string(6) "â¬", un Mojibake
var_dump(utf8_decode('€')); // string(1) "?", byte inválido
Exacto: todo está roto, el signo € llegó más tarde, en ISO-8859-15! ¡Nunca uses estas dos funciones!
Hacer una aplicación «Unicode Ready»
La primera cosa para hacer consiste obviamente en usar UTF-8. Tus archivos PHP tienen que ser codificados con una codificación compatible ASCII para que le parseador encuentre <?php.
Otra alternativa sería usar --enable-zend-multibyte al momento de compilar PHP y declare(encoding='UTF-16LE'); pero es mucho trabajo solo para el lujo de desarrollo sin compatibilidad ASCII – luego de algunas búsquedas, pareciera que este flag esta usado en Japón.
La otra opción muy importante de PHP es default_charset! Desde PHP 5.6, está configurada con UTF-8 por omisión: entonces todos tus scripts devuelven un header Content-Type UTF-8 por omisión si no especificas otro.
El intercambio de datos
Al requerir una página web, se transmite texto entre varios sistemas:
– de la base de datos a tu motor PHP;
– de tu servidor HTTP a tu navegador.
En cada intercambio de datos sí o sí interviene una codificación y hay que asegurarse que es la correcta. Es lo que hacemos con el header Content-Type: precisamos a nuestro navegador que el contenido esté transmitido en UTF-8 (u otro):
Content-Type: text/html; charset=utf-8
Existe también el tag HTML <meta charset="utf-8" /> pero no es muy inteligente, el navegador tiene que leer el HTML para saber como leer el HTML.
Con la base de datos se vuelve más complejo: ¿¡sabías que la codificación por omisión de una conexión MySQL depende de muchos criterios y que por lo general es… latin1!?
Aunque tu table haya sido creada con un charset=utf8, es posible que PHP intercambie en latin1 con MySQL.
// Ninguna codificación, hay riesgo que se use latin1
new PDO('mysql:dbname=foo;host=localhost', 'root', '');
// Codificación establecida en la cadena de conexión
new PDO('mysql:dbname=foo;host=localhost;charset=utf8','root', '');
// o justo después de la conexión:
'SET NAMES utf8;'
Es posible que tu sitio funcione aunque no hayas necesitado nunca precisar la codificación de la conexión, pero es también posible que todos tus datos estén corruptos sin que lo sepas.
Tomemos el ejemplo de «Loïck» que se suscribe en tu sitio web UTF-8, en una tabla UTF-8, pero con una conexión Latin1 :
– INSERT Loïck en UTF-8: 6 bytes, 5 chars;
– Transmisión en latin1, se realiza una conversión;
– Loïck está transmitido como Loïck: 6 bytes, 6 chars;
– Loïck está almacenado en UTF-8: 8 bytes, 6 chars;
– Luego hacemos un SELECT;
– Loïck UTF-8 transmitido en latin1: 6 bytes, 6 chars;
– Loïck mostrado en UTF-8, o sea Loïck!
¡Aceptarás el hecho que precisar la codificación de la conexión es obligatorio! El ORM Doctrine, por ejemplo, llama automáticamente SET NAMES utf8; si no estableciste una opción de charset.
Tu responsabilidad de desarrollador web
Dear @acmadotgov, please learn to unicode. These characters are found on the English iOS keyboard. The name is valid. Your assumption isn’t. pic.twitter.com/geRRiQrEC8
— Milorad Ivović (@ivovic) 30 septembre 2016

Este tweet de Milorad Ivović ilustra muy bien el problema: no puede inscribirse en un sitio gubernamental de Australia usando su propio apellido. U+0107 LATIN SMALL LETTER C WITH ACUTE es parte integrante de Unicode desde la versión 1.1, pero el sitio en cuestión decidió que solo ASCII estaba autorizado y propone como ejemplo el apellido más común posible: «Smith».
Unicode propone cerca de 260.000 posibilidades y es tu responsabilidad de ser inclusivo: tu aplicación Web debe poder ser utilizada por todo el mundo, sin importar el nombre, origen o cultura de tus visitantes.
El único argumento válido hoy en día para cometer tal error sería la seguridad y los eventuales problemas que un usuario «🍕» podría generar. Pero siguiendo algunas recomendaciones simples, el soporte completo de Unicode no debería causar problemas.
La normalización
¿Entonces quieres soportar Unicode sin límites y autorizar «🍕» como nombre de usuario? Es una excelente noticia, pero querrás también asegurarte que esta pizza es única en tu base de usuarios. Como lo sabes, tus usuarios van a ingresar cualquier cosa y podrías encontrarte con colisiones de identificador sin entender el porqué.
Existen dos fuentes posibles de colisión:
– los homoglyphs;
– los glyphs compuestos.
La composición, ya lo vimos, es el hecho de escribir «é» de dos maneras:
– é : U+00E9 LATIN SMALL LETTER E WITH ACUTE;
– e + ◌́ : U+0065 LATIN SMALL LETTER E seguido por U+0301 COMBINING ACUTE ACCENT.
Los homoglyphs son todavía más viciosos: se trata de caracteres que son visualmente idénticos pero tienen «code points» diferentes (y un significado diferente):
– K : U+212A KELVIN SIGN;
– K : U+004B LATIN CAPITAL LETTER K.
O también:
– Ω : U+03A9 GREEK CAPITAL LETTER OMEGA
– Ω : U+2126 OHM SIGN
Visualmente, todas estas variantes son estrictamente idénticas y, si el usuario se inscribe con la segunda forma, puedes estar seguro que querrá conectarse con la primera. Te toca a ti usar la normalización apropiada.
La normalización es la etapa que consiste en volver é y e + ◌́ idénticos con el fin de poder compararlos y ordenarlos de manera correcta. Todas las reglas de transformación ya están en el estándar, de manera que es bastante simple usarlas en muchos lenguajes:
$ARing = "\xC3\x85"; // Å (U+00C5) $ARingComposed = "A"."\xCC\x8A"; // A◌̊ (U+030A) $norm1 = Normalizer::normalize( $ARing, Normalizer::FORM_C ); $norm2 = Normalizer::normalize( $ARingComposed, Normalizer::FORM_C ); var_dump($ARing === $ARingComposed); // FALSE var_dump($norm1 === $norm2); // TRUE
Lo importante es ser consistente y estar al día: si normalizas en un lugar, hay que normalizar en todas partes. No como GitHub…
En 2016, su sistema de recuperación de contraseña ha sido víctima de un ataque por homoglyph. El email ingresado estaba normalizado al momento del SELECT en la base de datos, pero el vínculo de recuperación de contraseña estaba enviado al email de origen, sin normalización. Entonces, un atacante que quiere robar la cuenta mike@example.org podía cambiar la contraseña creándose una cuenta con miᏦᎬ@example.org, un email compuesto por homoglyphs.
Almacenamiento y MySQL
Algunas fallas ligadas a Unicode pueden ser vinculadas con el almacenamiento. Tomemos por ejemplo WordPress. El motor de blog acepta comentarios en HTML y en 2014 eso abrió una falla XSS ligada al soporte de Unicode de MySQL. Y sí: ¡era posible hackear WordPress con un trozo de 🍕!
Si se somete el comentario siguiente, pasará la etapa de validación del HTML sin error (es código válido):
<abbr title='🍕'>H4x0r</abbr>
Pero al momento de la inserción en la base de datos, solo el inicio: <abbr title=' estaba escrito en la tabla de los comentarios. Entonces este tag mal cerrado provoca un bug de HTML que va a ser explotable insertando un segundo comentario, igualmente válido, que puede escribir cualquier atributo HTML:
hola' onmouseover='alert(1)'
Mismo problema en 2014 sobre Phabricator, cuyo sistema de inscripción efectuaba una validación del nombre de dominio de la dirección email, y podía ser engañado mediante la adición de un carácter mal almacenado por MySQL.
Creando una cuenta con attacker@gmail.com🍕@allowed-domain.com la verificación del dominio funcionaba correctamente, pero solo attacker@gmail.com estaba escrito en la tabla MySQL.
Estas dos fallas de seguridad tienen la misma fuente: el charset utf8 de MySQL. Este charset sigue siendo utilizado por omisión en muchas instalaciones, pero tiene un grave problema: no soporta UTF-8 entero, sino solamente la BMP (los 65k códigos más útiles).
Otro problema: el modo strict de MySQL está también desactivado por omisión. Esta combinación explosiva hace que si tratamos de insertar un carácter fuera de la BMP, nuestra cadena estará truncada a partir de este carácter y ningún error será reportado.
La solución es muy simple: ¡tienes que usar el charset utf8mb4! Si sigues usando utf8, tu sitio no soporta los emojis, hay un grave problema.
Para concluir
– Go Unicode: tienes que ser inclusivo y hacer el esfuerzo necesario para soportar los usuarios del mundo entero;
– Establece el charset de tus conexiones MySQL;
– Deja de usar el charset utf8 en tus tablas, está mal nombrado, obsoleto y peligroso;
– Usa utf8mb4, es el bien;
– Normaliza los contenidos importantes, para ordenar y comparar de manera homogénea;
– Fuerza la codificación para todos tus desarrolladores (con un EditorConfig por ejemplo);
– No uses utf8_decode ni utf8_encode!
La codificación y los problemas resultantes son relativamente poco estudiados pero muy presentes en la web. Aprendí mucho al escribir este artículo porque existe realmente una falta de pedagogía en este tema.
El trabajo del Consortium Unicode es absolutamente loco, y las herramientas para normalizar, ordenar, comparar, detectar palabras están publicados gratuitamente (ICU). Si lo deseas puedes apoyar su trabajo siendo padrino de un carácter – por nuestra parte ¡somos padrinos del emoji 🍻!
 Y ahora, ¡te invito a siempre probar de crear cuentas con el username 🍕 en los sitios que desarrollas!
Y ahora, ¡te invito a siempre probar de crear cuentas con el username 🍕 en los sitios que desarrollas!
Referencias
Traducción de L’histoire d’Unicode et son adoption sur le Web.
Autor: Damien Alexandre
Fecha: 09 de noviembre de 2016
Traducción: Sylvain Lesage.